01. Reynold Xin, Databricks, Visits #theCUBE. (00:20)
02. Building Out the Streaming Stack. (00:48)
03. Out of Order Data and Time Accuracy. (05:51)
04. Similarities for Developers Between SQL and Spark. (10:35)
05. The Query Optimizer. (14:35)
06. Community Edition of Databricks. (18:01)
07. Spark Notebooks for a Less Technical Audience. (19:39)
Track List created with http://www.vinjavideo.com.
https://siliconangle.com/2016/02/18/a-new-model-of-data-with-streaming-and-spark-sparksummit/
--- ---
A new model of data with streaming and Spark | #SparkSummit
by Nelson Williams | Feb 18, 2016
Streaming data is changing the way people look at Big Data processing. The benefit of streaming is that data can be used as it comes in, rather than waiting for it to be sorted, stored and evaluated. In a market where data-driven customer interactions happen in seconds, this is a huge advantage.
To help bring streaming data into focus, Jeff Frick and George Gilbert, cohosts of theCUBE, from the SiliconANGLE Media team, joined Reynold Xin at the Spark Summit East 2016 conference. Xin is the cofounder and chief architect for Spark at Databricks, Inc.
Harnessing the power of streaming
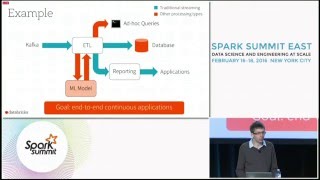
The conversation started with a quick overview of streaming. “Streaming is a very important piece in the whole data ecosystem,” Xin said. He noted that streaming is a response to the demand to act faster on data. However, streaming can be complex. Companies, he said, need integration between streaming and their current infrastructure, which isn’t easy. Because of this, there are a number of approaches to streaming in the industry. At Databricks, he said, they’ve been working on the question of how to make streaming simple.
Part of this process is raising the level of abstraction with Apache Spark so the user only needs to tell the system what to do, leaving it for Spark to figure out how to do it. This works because Spark will self-correct when new data comes in from the stream. Even if it doesn’t have all the data, the system can at least give an answer of some kind.
Working with a new model
Although Spark and streaming data is new compared to traditional methods, classical programmers shouldn’t have to unlearn their skills. Xin pointed out the main difference is some tools have been made more general and powerful and then embedded into Spark. Spark also opened up some internals to enable a wider range of applications.
As to what’s next, Xin said the goal was to make the Spark learning experience easier. He mentioned the Databricks Community Edition, a free version of its cloud-based Spark platform, meant to help people learn Spark. Also, he said, there was some discussion of developing a drag-and-drop widget for a less technical audience.
@theCUBE
#SparkSummit
Forgot Password
Almost there!
We just sent you a verification email. Please verify your account to gain access to
Spark Summit East 2016 | New York. If you don’t think you received an email check your
spam folder.
In order to sign in, enter the email address you used to registered for the event. Once completed, you will receive an email with a verification link. Open this link to automatically sign into the site.
Register For Spark Summit East 2016 | New York
Please fill out the information below. You will recieve an email with a verification link confirming your registration. Click the link to automatically sign into the site.
You’re almost there!
We just sent you a verification email. Please click the verification button in the email. Once your email address is verified, you will have full access to all event content for Spark Summit East 2016 | New York.
I want my badge and interests to be visible to all attendees.
Checking this box will display your presense on the attendees list, view your profile and allow other attendees to contact you via 1-1 chat. Read the Privacy Policy. At any time, you can choose to disable this preference.
Select your Interests!
add
Upload your photo
Uploading..
OR
Connect via Twitter
Connect via Linkedin
EDIT PASSWORD
Share
Forgot Password
Almost there!
We just sent you a verification email. Please verify your account to gain access to
Spark Summit East 2016 | New York. If you don’t think you received an email check your
spam folder.
In order to sign in, enter the email address you used to registered for the event. Once completed, you will receive an email with a verification link. Open this link to automatically sign into the site.
Sign in to gain access to Spark Summit East 2016 | New York
Please sign in with LinkedIn to continue to Spark Summit East 2016 | New York. Signing in with LinkedIn ensures a professional environment.
Are you sure you want to remove access rights for this user?
Details
Manage Access
email address
Community Invitation
Reynold Xin, Databricks - #SparkSummit East 2016 - #theCUBE
01. Reynold Xin, Databricks, Visits #theCUBE. (00:20)
02. Building Out the Streaming Stack. (00:48)
03. Out of Order Data and Time Accuracy. (05:51)
04. Similarities for Developers Between SQL and Spark. (10:35)
05. The Query Optimizer. (14:35)
06. Community Edition of Databricks. (18:01)
07. Spark Notebooks for a Less Technical Audience. (19:39)
Track List created with http://www.vinjavideo.com.
https://siliconangle.com/2016/02/18/a-new-model-of-data-with-streaming-and-spark-sparksummit/
--- ---
A new model of data with streaming and Spark | #SparkSummit
by Nelson Williams | Feb 18, 2016
Streaming data is changing the way people look at Big Data processing. The benefit of streaming is that data can be used as it comes in, rather than waiting for it to be sorted, stored and evaluated. In a market where data-driven customer interactions happen in seconds, this is a huge advantage.
To help bring streaming data into focus, Jeff Frick and George Gilbert, cohosts of theCUBE, from the SiliconANGLE Media team, joined Reynold Xin at the Spark Summit East 2016 conference. Xin is the cofounder and chief architect for Spark at Databricks, Inc.
Harnessing the power of streaming
The conversation started with a quick overview of streaming. “Streaming is a very important piece in the whole data ecosystem,” Xin said. He noted that streaming is a response to the demand to act faster on data. However, streaming can be complex. Companies, he said, need integration between streaming and their current infrastructure, which isn’t easy. Because of this, there are a number of approaches to streaming in the industry. At Databricks, he said, they’ve been working on the question of how to make streaming simple.
Part of this process is raising the level of abstraction with Apache Spark so the user only needs to tell the system what to do, leaving it for Spark to figure out how to do it. This works because Spark will self-correct when new data comes in from the stream. Even if it doesn’t have all the data, the system can at least give an answer of some kind.
Working with a new model
Although Spark and streaming data is new compared to traditional methods, classical programmers shouldn’t have to unlearn their skills. Xin pointed out the main difference is some tools have been made more general and powerful and then embedded into Spark. Spark also opened up some internals to enable a wider range of applications.
As to what’s next, Xin said the goal was to make the Spark learning experience easier. He mentioned the Databricks Community Edition, a free version of its cloud-based Spark platform, meant to help people learn Spark. Also, he said, there was some discussion of developing a drag-and-drop widget for a less technical audience.
@theCUBE
#SparkSummit