01. Kickoff Day 1, Spark Summit East 2016 #theCUBE!. (00:19)
02. The Business Impact of Spark and Tungsten. (01:24)
03. DataBricks, InMemory and Spark's Impact. (02:43)
04. How Spark Came About and How Its Growing. (04:44)
05. Sampling is Dead. (06:19)
06. Simplifying the Data Lake: George Gilbert's Research Findings. (07:51)
07. Moving Away from Hadoop Towards Spark-Like Systems. (10:27)
08. The Lack of Packaged Apps and the Need for Customization. (11:45)
09. Tighter Integration and Faster Response. (13:12)
Track List created with http://www.vinjavideo.com.
--- ---
Key study reveals evolution of enterprise Big Data, storage | #SparkSummit
by Marlene Den Bleyker | Feb 17, 2016
Kicking off theCUBE’s coverage of Spark Summit East 2016, Dave Vellante and George Gilbert, cohosts of theCUBE, from the SiliconANGLE Media team, discussed a recent study performed by Gilbert, who is also a Wikibon analyst, to discover the key takeaways of where the enterprise stands with Big Data and storage (full video below).
The study — comprised of roughly 40 companies, practitioners and users — revealed the following insights:
Key #1: Customer journey
“There are three stages in customer journey,” Gilbert said. “This is the most important way for vendors and doers to understand how they are going to apply the technology.”
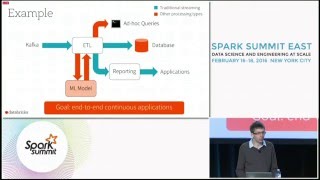
The first stage is creating the data lake. Gilbert feels that classically this is done on the Hadoop platform but believes that some elements work better with Spark. The second stage consists of moving away from Hadoop to Spark with real-time personalized systems. Lastly is moving data through autonomous software that can take action on the Internet of Things.
Gilbert underscored that the key element is real-time capabilities.
Key #2: The need for apps
The need for applications is key #2. “Last year we made an assumption the only way it will work is if we do have apps to scale,” Gilbert said. But, this hasn’t happened, and according to the survey, there are no packaged apps in the near future.
This means the enterprise will have handcrafted solutions for several years out, resulting in slower growth for the overall market.
Key #3: Real time is BIG
Gilbert found that there is tighter integration with the systems of record, the core back-end apps, and essentially anything that is controlling access to resources. There are also apps at edge supporting the digital experience. He finds Spark to be the better platform for tightening and coupling of computing components in order to make a claim on resources.
The team will unpack the findings throughout the Spark Summit conference, which is hosted by Databricks, Inc. in New York City.
@theCUBE
#SparkSummit
Forgot Password
Almost there!
We just sent you a verification email. Please verify your account to gain access to
Spark Summit East 2016 | New York. If you don’t think you received an email check your
spam folder.
In order to sign in, enter the email address you used to registered for the event. Once completed, you will receive an email with a verification link. Open this link to automatically sign into the site.
Register For Spark Summit East 2016 | New York
Please fill out the information below. You will recieve an email with a verification link confirming your registration. Click the link to automatically sign into the site.
You’re almost there!
We just sent you a verification email. Please click the verification button in the email. Once your email address is verified, you will have full access to all event content for Spark Summit East 2016 | New York.
I want my badge and interests to be visible to all attendees.
Checking this box will display your presense on the attendees list, view your profile and allow other attendees to contact you via 1-1 chat. Read the Privacy Policy. At any time, you can choose to disable this preference.
Select your Interests!
add
Upload your photo
Uploading..
OR
Connect via Twitter
Connect via Linkedin
EDIT PASSWORD
Share
Forgot Password
Almost there!
We just sent you a verification email. Please verify your account to gain access to
Spark Summit East 2016 | New York. If you don’t think you received an email check your
spam folder.
In order to sign in, enter the email address you used to registered for the event. Once completed, you will receive an email with a verification link. Open this link to automatically sign into the site.
Sign in to gain access to Spark Summit East 2016 | New York
Please sign in with LinkedIn to continue to Spark Summit East 2016 | New York. Signing in with LinkedIn ensures a professional environment.
Are you sure you want to remove access rights for this user?
Details
Manage Access
email address
Community Invitation
Kickoff Day 1 - #SparkSummit East 2016 - #theCUBE
01. Kickoff Day 1, Spark Summit East 2016 #theCUBE!. (00:19)
02. The Business Impact of Spark and Tungsten. (01:24)
03. DataBricks, InMemory and Spark's Impact. (02:43)
04. How Spark Came About and How Its Growing. (04:44)
05. Sampling is Dead. (06:19)
06. Simplifying the Data Lake: George Gilbert's Research Findings. (07:51)
07. Moving Away from Hadoop Towards Spark-Like Systems. (10:27)
08. The Lack of Packaged Apps and the Need for Customization. (11:45)
09. Tighter Integration and Faster Response. (13:12)
Track List created with http://www.vinjavideo.com.
--- ---
Key study reveals evolution of enterprise Big Data, storage | #SparkSummit
by Marlene Den Bleyker | Feb 17, 2016
Kicking off theCUBE’s coverage of Spark Summit East 2016, Dave Vellante and George Gilbert, cohosts of theCUBE, from the SiliconANGLE Media team, discussed a recent study performed by Gilbert, who is also a Wikibon analyst, to discover the key takeaways of where the enterprise stands with Big Data and storage (full video below).
The study — comprised of roughly 40 companies, practitioners and users — revealed the following insights:
Key #1: Customer journey
“There are three stages in customer journey,” Gilbert said. “This is the most important way for vendors and doers to understand how they are going to apply the technology.”
The first stage is creating the data lake. Gilbert feels that classically this is done on the Hadoop platform but believes that some elements work better with Spark. The second stage consists of moving away from Hadoop to Spark with real-time personalized systems. Lastly is moving data through autonomous software that can take action on the Internet of Things.
Gilbert underscored that the key element is real-time capabilities.
Key #2: The need for apps
The need for applications is key #2. “Last year we made an assumption the only way it will work is if we do have apps to scale,” Gilbert said. But, this hasn’t happened, and according to the survey, there are no packaged apps in the near future.
This means the enterprise will have handcrafted solutions for several years out, resulting in slower growth for the overall market.
Key #3: Real time is BIG
Gilbert found that there is tighter integration with the systems of record, the core back-end apps, and essentially anything that is controlling access to resources. There are also apps at edge supporting the digital experience. He finds Spark to be the better platform for tightening and coupling of computing components in order to make a claim on resources.
The team will unpack the findings throughout the Spark Summit conference, which is hosted by Databricks, Inc. in New York City.
@theCUBE
#SparkSummit