Is simplifying Big Data possible? Databricks says yes | #SparkSummit
by Teryn O'Brien | Feb 17, 2016
When the Hadoop project (an open-source software for reliable, scalable, distributed computing) began, it became clear that things were far too complicated. So Databricks, Inc. set out to simplify the Big Data process with the Apache Spark project.
Dave Vellante and George Gilbert, cohosts of theCUBE, from the SiliconANGLE Media team, set down at Spark Summit East 2016 to speak with Ali Ghodsi, CEO of Databricks, to talk about the simplification of Big Data.
The advantages of Cloud
The implementation of Cloud has made everything a very different game, and Databricks is using this to its advantage with Apache Spark, the largest open-source project in data processing.
“This is one of the beauties of the Cloud,” Ghodsi said. “It’s up and running. It’s elastic. So you can compose those services and products that you need seamlessly.”
For admins, it’s easier because Databricks makes sure software updates are always integrated. The company only has two versions of its software running at all times in the Cloud. And it also releases updates every week. But with non-Cloud settings, things release every few months. “It’s continuously developing features and deploying them to customers,” said Ghodsi.
Big Data problems customers need solved
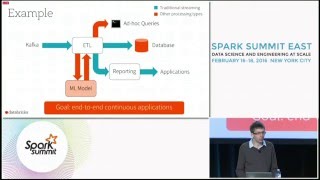
For businesses and Big Data, the problem that Databricks is attacking has many pieces. First, companies have already stored data, but the data is siloed and they can’t make decisions on it. Second, there was the problem of unifying the use cases that companies have. Companies want to go further with advanced analytics. They want to cluster and segment the data they have.
They also want to do things in real time.
So one of the visions of Databricks’ Spark service is: How can Spark give businesses something that works end to end? “So unifying these is where we provide value to the customer,” said Ghodsi.
Ali Ghodsi, CEO of Databricks, Inc. spoke with theCUBE about Databrick’s vision to simplify Spark and provide turnkey solutions to solve customer problems surrounding data silos to extract value from disparate data.
Uncomplicating Spark
“We were involved in the Hadoop projects, and what we saw was that really simple operations were extremely complicated. … We want to be part of that journey to simplify. So if companies can extract insights more easily, it lowers their costs, and they can do great things with it.”
“One of the visions of Spark, and what we provide is how do we give them something that works end to end, so its turnkey, rather than having to stitch together different pieces. We use the term unifying. So it is unifying different use cases.”
Unifying use cases
“Unifying these [use cases] is where you provide value to the customer — not having the siloed data and being able to unify the use cases companies have so that they can have end-to-end built pipelines that solve the problems and give the turnkey solutions they need.”
@theCUBE
#SparkSummit
Forgot Password
Almost there!
We just sent you a verification email. Please verify your account to gain access to
Spark Summit East 2016 | New York. If you don’t think you received an email check your
spam folder.
In order to sign in, enter the email address you used to registered for the event. Once completed, you will receive an email with a verification link. Open this link to automatically sign into the site.
Register For Spark Summit East 2016 | New York
Please fill out the information below. You will recieve an email with a verification link confirming your registration. Click the link to automatically sign into the site.
You’re almost there!
We just sent you a verification email. Please click the verification button in the email. Once your email address is verified, you will have full access to all event content for Spark Summit East 2016 | New York.
I want my badge and interests to be visible to all attendees.
Checking this box will display your presense on the attendees list, view your profile and allow other attendees to contact you via 1-1 chat. Read the Privacy Policy. At any time, you can choose to disable this preference.
Select your Interests!
add
Upload your photo
Uploading..
OR
Connect via Twitter
Connect via Linkedin
EDIT PASSWORD
Share
Forgot Password
Almost there!
We just sent you a verification email. Please verify your account to gain access to
Spark Summit East 2016 | New York. If you don’t think you received an email check your
spam folder.
In order to sign in, enter the email address you used to registered for the event. Once completed, you will receive an email with a verification link. Open this link to automatically sign into the site.
Sign in to gain access to Spark Summit East 2016 | New York
Please sign in with LinkedIn to continue to Spark Summit East 2016 | New York. Signing in with LinkedIn ensures a professional environment.
Are you sure you want to remove access rights for this user?
Details
Manage Access
email address
Community Invitation
Ali Ghodsi, Databricks - #SparkSummit East 2016 - #theCUBE
Is simplifying Big Data possible? Databricks says yes | #SparkSummit
by Teryn O'Brien | Feb 17, 2016
When the Hadoop project (an open-source software for reliable, scalable, distributed computing) began, it became clear that things were far too complicated. So Databricks, Inc. set out to simplify the Big Data process with the Apache Spark project.
Dave Vellante and George Gilbert, cohosts of theCUBE, from the SiliconANGLE Media team, set down at Spark Summit East 2016 to speak with Ali Ghodsi, CEO of Databricks, to talk about the simplification of Big Data.
The advantages of Cloud
The implementation of Cloud has made everything a very different game, and Databricks is using this to its advantage with Apache Spark, the largest open-source project in data processing.
“This is one of the beauties of the Cloud,” Ghodsi said. “It’s up and running. It’s elastic. So you can compose those services and products that you need seamlessly.”
For admins, it’s easier because Databricks makes sure software updates are always integrated. The company only has two versions of its software running at all times in the Cloud. And it also releases updates every week. But with non-Cloud settings, things release every few months. “It’s continuously developing features and deploying them to customers,” said Ghodsi.
Big Data problems customers need solved
For businesses and Big Data, the problem that Databricks is attacking has many pieces. First, companies have already stored data, but the data is siloed and they can’t make decisions on it. Second, there was the problem of unifying the use cases that companies have. Companies want to go further with advanced analytics. They want to cluster and segment the data they have.
They also want to do things in real time.
So one of the visions of Databricks’ Spark service is: How can Spark give businesses something that works end to end? “So unifying these is where we provide value to the customer,” said Ghodsi.
Ali Ghodsi, CEO of Databricks, Inc. spoke with theCUBE about Databrick’s vision to simplify Spark and provide turnkey solutions to solve customer problems surrounding data silos to extract value from disparate data.
Uncomplicating Spark
“We were involved in the Hadoop projects, and what we saw was that really simple operations were extremely complicated. … We want to be part of that journey to simplify. So if companies can extract insights more easily, it lowers their costs, and they can do great things with it.”
“One of the visions of Spark, and what we provide is how do we give them something that works end to end, so its turnkey, rather than having to stitch together different pieces. We use the term unifying. So it is unifying different use cases.”
Unifying use cases
“Unifying these [use cases] is where you provide value to the customer — not having the siloed data and being able to unify the use cases companies have so that they can have end-to-end built pipelines that solve the problems and give the turnkey solutions they need.”
@theCUBE
#SparkSummit